
Predicting Whether an online Job Post is Fraudulent


Introduction
In the US, the Federal Trade Commission (FTC) is a leading authoritative voice on identifying and reporting employment scams. The FTC advises job-seekers to use heuristics to wade through potential scams. Advise includes: find jobs using only trusted sources, perform a Google search of the company name and include keywords like ‘scam,’ or ‘complaint,’ and do not pay any amount of money to untrusted sources. However, there is currently no data-backed tool that prospective employees can use to help identify fraudulent employment offers and labor fraud. This is concerning since malicious content generally aims to be indistinguishable from benign content. The following report illustrates one example of how text analytics can offer a solution. The data is retrievable from Kaggle and was originally derived from the Employment Scam Aegean Dataset (EMSCAD).
The image above is a theoretical dashboard that could be created to fully realize the aim of our project.

Normalization (TF-IDF) & Dimension Reduction (SVD)
Term frequency-inverse document frequency (TF-IDF) was used to evaluate the relative importance of each word in the corpus. Word clouds were produced in Python after performing TF-IDF to exclude stop words and insignificant words from the visualization.
Singular-Value Decomposition (SVD) is a matrix decomposition method used to reduce a complex matrix into its constituent parts so the subsequent calculations are easier and simpler (Brownlee 2018). In this project, the TF-IDF matrix of the training data could be as large as 15 million columns - a computationally impossible size for modelling on our machines. SVD is an effective way to reduce the size of the data in memory while preserving the usefulness of the original data. For this application, the intractably large TF-IDF matrix was decomposed into 20 singular vectors.
Source: Brownlee, Jason. “How to Calculate the SVD from Scratch with Python.” Machine Learning Mastery, 18 Oct. 2019, machinelearningmastery.com/singular-value-decomposition-formachine-learning/

Challenges
Missing Values
There was a high frequency of missing values throughout the dataset. Initially, this was viewed as a concern. However, it became clear that a missing field in a job posting could itself be useful in predicting whether the posting was fraudulent. For example, job postings that lack a company profile are more likely to be fraudulent.
Unstructured Text
Four of the key columns in the data were unstructured text fields of unpredictable length. The fields could be quite long and analysis using the data required substantial computational resources.
To illustrate the point further, simply pasting the text contents of a single job description into Word could require two pages of single-spaced content. In addition, some of the code chunks can take as long as 30 minutes to run (depending on the user's machine).
Highly Imbalanced
The presence of a highly class-imbalanced dataset required innovative data manipulation to avoid overtraining the models. In this setting, a naïve model could erroneously classify a large percentage of the data as the dominant variable, resulting in a misleadingly high accuracy rating. This bias is even greater for high-dimensional data. In general, under- or oversampling are two methods that can help to mitigate the class-imbalance problem.
Solving Class-Imbalance: SMOTE
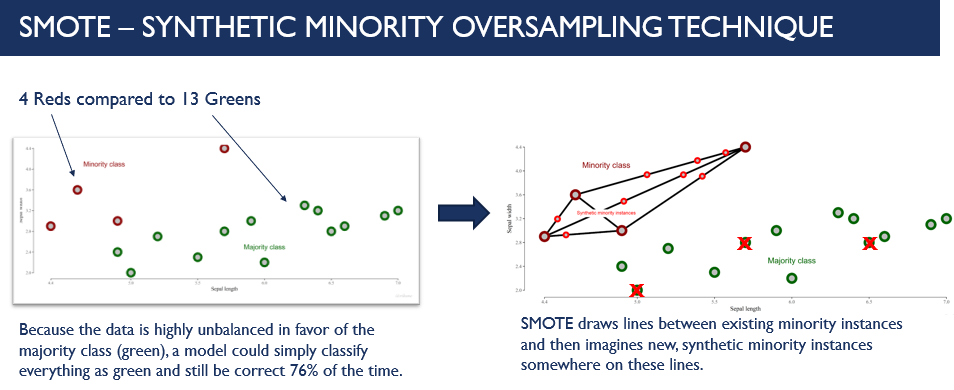
Implementing a machine learning algorithm is problematic when the composition of the target variable in the training set is highly unbalanced. Synthetic Minority Over Sampling Technique (SMOTE) is a popular strategy used to attenuate the class-imbalance problem. An improvement from merely duplicating points from the minority class, SMOTE uses kNN and Euclidian distances to generate a feature space. A line is drawn between the nearest N existing minority points in the feature space and populated with synthesized points. SMOTE is commonly paired with random under sampling of the majority class in order to fully balance the dataset.
There are a multitude of practical consequences to consider when using SMOTE. For example, as the number of variables increases, the polarity between the two variables is heightened and the “nearest neighbor” to the test samples can be one of the SMOTE samples. In this case, SMOTE is likely to bias classification towards the minority class.
In another instance, SMOTE has potential to be problematic for “classifiers that assume independence among samples” - penalized logistic regression, for example. This means variable selection after performing SMOTE should be done with careful regard since most variable selection methods presuppose sample independence. Finally, even though the overall expected value of the SMOTE augmented minority class is equal to the expected value of the original minority class, its variance is smaller.

Insights
Fraudulent job postings are more likely to omit a company logo and are less likely to provide screening questions. It is intriguing to note that neither the FTC nor popular job search engines warn prospective employees to look for a company logo
Although a plethora of resources warn jobseekers to be wary of “work-from-home" schemes that overpromise the ease of working from the comfort of your living room, this project revealed the presence of a Telecommute offer was not as significant as the presence of a company logo
The US and Australia are associated with more fraud than locations in Europe (note the potential for bias since all posts in the dataset are in English)
Fraudulent job posts tended to have fewer characters and fewer words in the company profile. This is unsurprising since it seems likely that scammers looking to make quick money are less likely to compose meticulous job advertisements
Fraudulent jobs posts are more likely to leave the Requirements and Benefits sections blank

Interested?
Email me if you are interested in viewing copies of the completed project submission.
eafogg@smu.edu